Ciele
- Naučiť sa určovať výberové charakteristiky náhodného výberu.
- Naučiť sa určovať bodové odhady parametrov \(\mu\) a \(\sigma\) základného súboru s normálnym rozdelením.
- Naučiť sa určovať intervaly spoľahlivosti pre strednú hodnotu \(\mu\) základného súboru s normálnym rozdelením, ak poznáme smerodajnú odchýlku \(\sigma\).
- Naučiť sa určovať intervaly spoľahlivosti pre strednú hodnotu \(\mu\) základného súboru s normálnym rozdelením, ak nepoznáme smerodajnú odchýlku \(\sigma\).
- Naučiť sa určovať intervaly spoľahlivosti pre rozptyl \(\sigma^2\) a smerodajnú odchýlku \(\sigma\) základného súboru s normálnym rozdelením, ak nepoznáme strednú hodnotu \(\mu\).
Úvod
-
Úlohou bodových odhadov je nájsť odhad parametra základného súboru pomocou jednej číselnej hodnoty. Za bodové odhady parametrov
slúžia niektoré tzv. výberové charakteristiky.
Intervalový odhad umožňuje určiť nielen jeden najlepší odhad, ale celý interval pravdepodobne možných odhadov parametra základného súboru. Interval, v ktorom sa pravdepodobne nachádza parameter základného súboru, sa nazýva interval spoľahlivosti (konfidenčný interval). Podľa toho, či určujeme v intervale spoľahlivosti jednu alebo dve hranice, rozoznávame jednostranný (pravostranný, ľavostranný) alebo obojstranný interval spoľahlivosti.
Bodový odhad je prvá informácia o parametroch daného rozdelenia, v praxi však zvyčajne nestačí. Aby sme mohli ohraničiť chybu, ktorej sa dopúšťame pri odhade, používame na určenie odhadu sledovaných parametrov intervaly spoľahlivosti.
Prípustná chyba, tzv. hladina významnosti sa označuje gréckym písmenom \(\alpha\), \(1-\alpha\) je koeficient spoľahlivosti a príslušný interval spoľahlivosti nazývame (\(1-\alpha\))\(\cdot100\) %-ný interval spoľahlivosti. Znamená to, že ak by sme urobili veľký počet meraní (výberových súborov) zo sledovanej náhodnej premennej a pre každý súbor by sme určili príslušný interval spoľahlivosti, tak v (\(1-\alpha\))\(\cdot100\) % prípadoch by skutočná hodnota hľadaného parametra ležala v intervale spoľahlivosti. \(\def\a{&}\)
Postup
-
Výberové charakretistiky náhodného výberu
V štatistike sa používa tzv. výberová metóda, ktorá spočíva v tom, že opis určitého štatistického súboru a závery o ňom opierame o údaje, týkajúce sa len vybraných jednotiek tohto súboru. Teda základným princípom výberovej metódy je usudzovanie z časti na celok. Súbor, ktorý je predmetom výskumu potom nazývame základný súbor a súbor jednotiek, ktoré boli z neho určitým spôsobom vybrané, nazývame výberový súbor.
Štatistický súbor je možné opísať pomocou rôznych opisných charakteristík, z ktorých najdôležitejšími sú aritmetický priemer, rozptyl a smerodajná odchýlka. Neznáme opisné charakteristiky základného súboru sa odhadujú pomocou príslušných výberových štatistík (charakteristík).
Ak vyberieme zo základného súboru \(n\) jednotiek, t. j. ak urobíme náhodný výber \(V_n\) o rozsahu \(n\), a ak zistíme u každej vybranej jednotky hodnotu znaku \(X\), potom získame \(n\) výberových hodnôt (realizácií, nameraných hodnôt) \(x_{1},\,x_{2},\,\dots ,\,x_{n}\).
Nech je daný náhodný výber \(V_n\) o rozsahu \(n\), kde \(x_{1},\,x_{2},\,\dots ,\,x_{n}\) sú namerané hodnoty. Teraz uvedieme definície základných výberových charakteristík (štatistík), a to výberového priemeru, výberového rozptylu a výberovej smerodajnej odchýlky.
Výberový priemer \(\bar{x}\) a výberový rozptyl \(s^2\) budeme definovať ako čísla, ktoré môžeme pre neroztriedený výberový súbor počítať použitím vzorcov v tzv. prostom tvare \(\bar{x}=\frac{1}{n}\sum\limits_{i=1}^{n} x_i\),\(\,\) \(\ \) \(s^2=\frac{1}{n-1}\sum\limits_{i=1}^{n} (x_i-\bar{x})^2\), kde \(x_i\) sú namerané hodnoty a \(n\) je rozsah náhodného výberu, t. j. počet vybraných štatistických jednotiek (prvkov) zo základného súboru.
V prípade roztriedeného súboru vo forme tzv. frekvenčnej tabuľky (tabuľky rozdelenia absolútnych početností) môžeme použiť vzorce v tzv. váženom tvare: \(\bar{x}=\frac{1}{n}\sum\limits_{i=1}^{k} x_i\cdot n_i\),\(\,\) \(\ \) \(s^2=\frac{1}{n-1}\sum\limits_{i=1}^{k} (x_i-\bar{x})^2\cdot n_i\). V daných vzorcoch sú \(x_i\) hodnoty triediaceho znaku, \(n_i\) sú ich absolútne početnosti, n je rozsah výberového súboru, k je počet tried. V tomto prípade každý triediaci znak predstavuje samostatnú triedu. Platí: \(n=\sum\limits_{i=1}^{k} n_i\).
V prípade intervalového triedenia do intervalov \(I_i\) použijeme v uvedených vzorcoch namiesto hodnôt \(x_i\) triediaceho znaku hodnoty triedneho znaku \(z_i\). Triedny znak \(z_i\) je reprezentantom triedneho intervalu (triedy) \(I_i\). Definuje sa ako stred príslušného triedneho intervalu.
Výberová smerodajná odchýlka \(s\) náhodného výberu sa definuje vzťahom: \(s\ =\sqrt{s^2}\).Príklad:
Pre dané výberové súbory vypočítajte výberové charakteristiky, t. j. výberový priemer, výberový rozptyl a výberovú smerodajnú odchýlku.- V zimnom období zisťovali stav hladiny spodnej vody v zosuvovej oblasti. Namerali takéto stavy [\(\mathrm{cm}\)]: 159,53; 159,49; 159,61; 159,71; 159,88; 161,08; 160,98; 161,09; 160,91; 160,79; 161,02; 160,96; 160,80.
- Percentuálny obsah medi v určitej zliatine je daný tabuľkou rozdelenia intervalových početností:
\(I_i\) \(n_i\) 2,8 - 3,1 4 3,1 - 3,4 7 3,4 - 3,7 11 3,7 - 4,0 18 4,0 - 4,3 23 4,3 - 4,6 10 4,6 - 4,9 2 4,9 - 5,2 1
-
Bodové odhady parametrov \(\mu\) a \(\sigma\) základného súboru s normálnym rozdelením
Ako sme už v predchádzajúcom cieli uviedli, neznáme číselné charakteristiky (resp. parametre) základného súboru sa odhadujú pomocou príslušných výberových charakteristík. My sa teraz sústredíme na bodový odhad (odhad jedným číslom) strednej hodnoty a smerodajnej odchýlky (resp. rozptylu) základného súboru s normálnym rozdelením, t. j. na bodový odhad jeho parametrov \(\mu\) a \(\sigma\), (resp. \(\sigma^2\)).
Nech \(Q\) je sledovaný parameter základného súboru a \(\hat Q\) je výberová charakteristika náhodného výberu \(V_n\) o rozsahu \(n\).
Bodovým odhadom parametra \(Q\) nazývame takú výberovú charakteristiku \(\hat Q\), ktorá nadobúda hodnoty blízke skutočnej hodnote parametra \(Q\).
Bodový odhad \(\hat Q\) nazývame nevychýleným bodovým odhadom parametra \(Q\), ak \(E(\hat Q)=Q\). Budeme používať zápis \(Q\approx \hat Q\).
Platí, že výberový priemer \(\bar{x}\) je nevychýleným bodovým odhadom strednej hodnoty \(\mu\), výberový rozptyl \(s^2\) je nevychýleným bodovým odhadom rozptylu \(\sigma^2\) a výberová smerodajná odchýlka \(s\) je nevychýleným bodovým odhadom smerodajnej odchýlky \(\sigma\) základného súboru s normálnym rozdelením \(norm(\mu,\,\sigma)\).Poznámka:
Pri odhadovaní parametrov základného súboru jedným číslom je potrebné zdôrazniť, že aj pri použití najvhodnejšieho bodového odhadu sa budeme dopúšťať chýb. Tieto chyby môžu byť niekedy aj „nepríjemne“ veľké, hlavne pri odhadoch, ktoré sa budú opierať o údaje výberov malého rozsahu. Práve pre túto skutočnosť sa odhady jedným číslom často dopĺňajú intervalovými odhadmi.Poznámka:
Existujú štatistické testy (tzv. testy dobrej zhody) umožňujúce na vopred zvolenej hladine významnosti \(\alpha\) testovať hypotézu, že daný náhodný výber bol realizovaný z rozdelenia stanoveného typu, ale prípadne s neznámymi parametrami. Teda je napríklad možné testovať hypotézu, že príslušné rozdelenie je normálne rozdelenie \(norm(\mu,\,\sigma)\) so známymi alebo neznámymi parametrami \(\mu\) a \(\sigma\). Tieto testy však nie sú obsahom nášho kurzu matematickej štatistiky.Príklad:
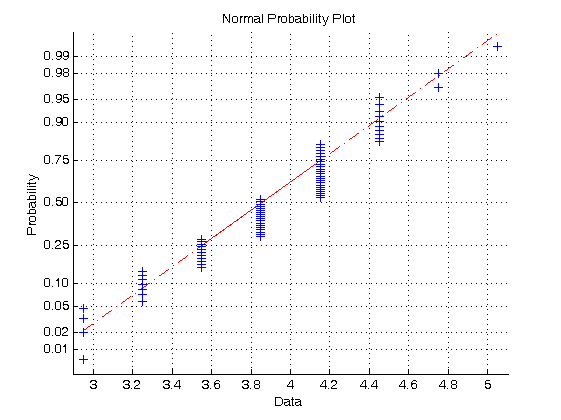
Grafickým testom s použitím MATLABu overte predpoklad normality rozdelenia základného súboru, z ktorého bol realizovaný náhodný výber uvedený v riešenej úlohe 1 b). Potom určte bodové odhady parametrov \(\mu\) a \(\sigma\). -
Intervaly spoľahlivosti pre strednú hodnotu \(\mu\) základného súboru s normálnym rozdelením, ak poznáme smerodajnú odchýlku \(\sigma\)
Intervalový odhad spočíva v tom, že neznámy parameter základného súboru odhadujeme určitým číselným intervalom, ktorý zostavujeme pomocou údajov získaných náhodným výberom. Keďže vyberáme náhodne, pripájame k danému intervalu aj pravdepodobnosť (t. j. spoľahlivosť odhadu), s ktorou je možné očakávať, že odhad bude správny.
Intervalové odhady pre parametre základného súboru sa udávajú trojakým spôsobom: buď sa ohraničia zhora aj zdola (obojstranné) alebo len z jednej strany (jednostranné), a to buď zdola (pravostranné) alebo zhora (ľavostranné).
Obojstranným intervalom spoľahlivosti pre parameter \(Q\) základného súboru nazývame odhad pomocou číselného intervalu \(\left\langle Q_d\ ;Q_h \right\rangle\), pričom pravdepodobnosť \(P(Q_d\le Q \le Q_h)= 1-\alpha\), kde hladina významnosti \(\alpha\in\left(0\, ; 1\right ) \).
Pravostranným intervalom spoľahlivosti pre parameter \(Q\) základného súboru nazývame odhad pomocou číselného intervalu \(\left\langle Q_d\ ; \infty\right ) \), pričom pravdepodobnosť \(P(Q\ge Q_d )= 1-\alpha\).
Ľavostranným intervalom spoľahlivosti pre parameter \(Q\) základného súboru nazývame odhad pomocou číselného intervalu \(\left( -\infty\ ; Q_h \right\rangle\), pričom pravdepodobnosť \(P(Q\le Q_h )= 1-\alpha\).
Interval spoľahlivosti označujeme aj pojmom (\(1-\alpha\))\(\cdot100\) %-ný interval spoľahlivosti, a to obojstranný, pravostranný, resp. ľavostranný.Poznámka:
Pri obojstrannom intervale spoľahlivosti sa \(Q_d\) a \(Q_h\) zvyčajne volia tak, aby pravdepodobnosti "chýbajúcich" intervalov zľava a sprava bolo rovnaké.
Pre intervalové odhady potrebujeme tzv. kvantilovú funkciu, ktorá je inverzná k distribučnej funkcii náhodnej premennej \(X\). Nech \(F(x)\) je distribučná funkcia náhodnej premennej \(X\) a nech \(\beta\in\left(0\, ; 1\right ) \). Kvantilová funkcia \(F^{-1}(\beta)\) je definovaná ako najmenšie číslo \(q\in \mathbb{R}\) také, že \(F(q)\geqq \beta\). Hodnotu \(q=F^{-1}(\beta)\) nazývame \(\beta\)-kvantilom v rozdelení pravdepodobnosti danom \(F(x)\).Poznámka:
Kvantily môžeme vyhľadať v tabuľkách, resp. môžeme použiť vhodný softvér (napr. my použijeme MATLAB). Určenie kvantilov si vysvetlíme neskôr na konkrétnych príkladoch.
Nech náhodná premenná \(X\) základného súboru má normálne rozdelenie pravdepodobnosti s parametrami \(\mu\in \mathbb{R}\) a \(\sigma\gt 0\), t. j. \(X\sim norm(\mu,\,\sigma)\), kde parameter \(\sigma\) poznáme. Nech \(n\) je rozsah náhodného výberu, \(\bar{x}\) je výberový priemer, hladina významnosti \(\alpha\in\left(0\, ; 1\right ) \) a \(y_\beta\) je \(\beta\)-kvantil normovaného normálneho rozdelenia \(norm(0,\,1)\).
S pravdepodobnosťou \(1-\alpha\) bude príslušný interval spoľahlivosti pre strednú hodnotu určený reláciou:- \(\mu\in\left\langle\bar{x}-y_{1-\alpha/2}\cdot\dfrac{\sigma}{\sqrt{n}}\ ; \bar{x}+y_{1-\alpha/2}\cdot\dfrac{\sigma}{\sqrt{n}} \right\rangle\), pre obojstranný
- \(\mu\in \left \langle \bar{x}-y_{1-\alpha}\cdot\dfrac{\sigma}{\sqrt{n}}\ ; \infty\! \ \right ) \), pre pravostranný
- \(\mu\in\left ( -\infty\ ; \bar{x}+y_{1-\alpha}\cdot\dfrac{\sigma}{\sqrt{n}} \right\rangle\), pre ľavostranný.
Príklad:
Zo základného súboru s normálnym rozdelením, kde je známy rozptyl \(\sigma^2=0{,}06\); sme urobili náhodný výber s realizáciami: 1,3; 1,8; 1,4; 1,2; 0,9; 1,5; 1,7. Zistite:- 95 %-ný obojstranný interval spoľahlivosti pre strednú hodnotu \(\mu\),
- 90 %-ný pravostranný interval spoľahlivosti pre strednú hodnotu \(\mu\),
- 99 %-ný ľavostranný interval spoľahlivosti pre strednú hodnotu \(\mu\).
-
Intervaly spoľahlivosti pre strednú hodnotu \(\mu\) základného súboru s normálnym rozdelením, ak nepoznáme smerodajnú odchýlku \(\sigma\)
Nech náhodná premenná \(X\) základného súboru má normálne rozdelenie pravdepodobnosti s parametrami \(\mu\in \mathbb{R}\) a \(\sigma\gt 0\), t.j. \(X\sim norm(\mu,\,\sigma)\), kde parameter \(\sigma\) nepoznáme. Nech \(n\) je rozsah náhodného výberu, \(\bar{x}\) je výberový priemer, \(s\) je výberová smerodajná odchýlka, hladina významnosti \(\alpha\in\left(0\, ; 1\right ) \) a \(t_{\beta,\,n-1}\) je \(\beta\)-kvantil Studentovho \(t\)-rozdelenia pravdepodobnosti s \(\gamma=n-1\) stupňami voľnosti.
S pravdepodobnosťou \(1-\alpha\) bude príslušný interval spoľahlivosti pre strednú hodnotu určený reláciou:- \(\mu\in\left\langle\bar{x}-t_{1-\alpha/2,\,n-1}\cdot\dfrac{s}{\sqrt{n}}\ ; \bar{x}+t_{1-\alpha/2,\,n-1}\cdot\dfrac{s}{\sqrt{n}} \right\rangle\) , pre obojstranný
- \(\mu\in \left \langle \bar{x}-t_{1-\alpha,\,n-1}\cdot\dfrac{s}{\sqrt{n}}\ ; \infty\! \ \right )\), pre pravostranný
- \( \mu\in\left ( -\infty\ ; \bar{x}+t_{1-\alpha,\,n-1}\cdot\dfrac{s}{\sqrt{n}} \right\rangle \), pre ľavostranný.
Príklad:
Zo základného súboru s normálnym rozdelením sme urobili náhodný výber s realizáciami: 22,4; 28,0; 20,1; 27,4; 25,6; 23,9; 24,8; 26,4; 27,0; 25,4. Zistite:- 95 %-ný obojstranný interval spoľahlivosti pre strednú hodnotu \(\mu\),
- 99 %-ný pravostranný interval spoľahlivosti pre strednú hodnotu \(\mu\),
- 90 %-ný ľavostranný interval spoľahlivosti pre strednú hodnotu \(\mu\).
-
intervaly spoľahlivosti pre rozptyl \(\sigma^2\) a smerodajnú odchýlku \(\sigma\) základného súboru s normálnym rozdelením, ak nepoznáme strednú hodnotu \(\mu\)
Nech náhodná premenná \(X\) základného súboru má normálne rozdelenie pravdepodobnosti s parametrami \(\mu\in \mathbb{R}\) a \(\sigma\gt 0\), t.j. \(X\sim norm(\mu,\,\sigma)\), kde parameter \(\mu\) nepoznáme. Nech \(n\) je rozsah náhodného výberu, \(s^2\) je výberový rozptyl, hladina významnosti \(\alpha\in\left(0\, ; 1\right ) \) a \(\chi^2_{\beta,\,n-1}\) je \(\beta\)-kvantil \(\chi^2\)-rozdelenia s \(\gamma=n-1\) stupňami voľnosti.
S pravdepodobnosťou \(1-\alpha\) bude príslušný interval spoľahlivosti pre rozptyl určený reláciou:- \(\sigma^2\in\left\langle \dfrac{(n-1)\cdot s^2}{\chi^2_{1-\alpha/2,\,n-1}}\ ;\dfrac{(n-1)\cdot s^2}{\chi^2_{\alpha/2,\,n-1}}\right\rangle\), pre obojstranný
- \(\sigma^2\in\left\langle \dfrac{(n-1)\cdot s^2}{\chi^2_{1-\alpha,\,n-1}}\ ;\, \infty \right)\), pre pravostranný
- \(\sigma^2\in\left ( 0\, ;\, \dfrac{(n-1)\cdot s^2}{\chi^2_{\alpha,\,n-1}}\right\rangle\), pre ľavostranný.
Poznámka:
Ak vo vzorcoch pre príslušné intervaly spoľahlivosti pre rozptyl \(\sigma^2\) odmocníme hranice, tak dostaneme vzorce pre príslušné intervaly spoľahlivosti pre smerodajnú odchýlku \(\sigma\):- \(\sigma\in\left\langle\sqrt{ \dfrac{(n-1)\cdot s^2}{\chi^2_{1-\alpha/2,\,n-1}}}\ ;\sqrt{\dfrac{(n-1)\cdot s^2}{\chi^2_{\alpha/2,\,n-1}}}\right\rangle\)
- \(\sigma\in\left\langle\sqrt{ \dfrac{(n-1)\cdot s^2}{\chi^2_{1-\alpha,\,n-1}}}\ ;\, \infty \right)\)
- \(\sigma\in\left (0\, ;\, \sqrt{\dfrac{(n-1)\cdot s^2}{\chi^2_{\alpha,\,n-1}}}\right\rangle\).
Príklad:
V laboratóriu bol meraný percentuálny obsah medi v zliatine. Výsledky meraní sú v tabuľke (\(z_i\) je triedny znak): \[ \begin{array}{|c|c|c|c|c|c|c|c|} \hline z_i \a 3{,}0 \a 3{,}3 \a 3{,}6 \a 3{,}9 \a 4{,}2 \a 4{,}5 \a 4{,}8 \\ \hline n_i \a 4 \a 7 \a 12 \a 18 \a 21 \a 13 \a 6 \\ \hline \end{array} \] Predpokladáme normálne rozdelenie základného súboru, z ktorého bol realizovaný náhodný výber. Určte:- 95 %-né obojstranné intervaly spoľahlivosti pre rozptyl \(\sigma^2\) a smerodajnú odchýlku \(\sigma\) obsahu medi v danej zliatine,
- 90 %-ný pravostranný interval spoľahlivosti pre rozptyl \(\sigma^2\) obsahu medi v danej zliatine,
- 99 %-ný ľavostranný interval spoľahlivosti pre rozptyl \(\sigma^2\) obsahu medi v danej zliatine.
Zdroje
- Ostertagová, E.: Aplikovaná štatistika. Equilibria, Košice, 2013, 218 s., ISBN 978-80-8143-067-1.
- Ostertagová, E.: Pravdepodobnosť a matematická štatistika v príkladoch. Elfa, Košice, 2005, 123 s., ISBN 80-8086-005-X.
Doplňujúce úlohy
- 99 %-ný obojstranný interval spoľahlivosti pre strednú hodnotu \(\mu\),
- 99 %-ný pravostranný interval spoľahlivosti pre strednú hodnotu \(\mu\),
- 95 %-ný ľavostranný interval spoľahlivosti pre strednú hodnotu \(\mu\).
- 95 %-ný obojstranný interval spoľahlivosti pre strednú hodnotu \(\mu\),
- 95 %-ný pravostranný interval spoľahlivosti pre strednú hodnotu \(\mu\),
- 95 %-ný ľavostranný interval spoľahlivosti pre strednú hodnotu \(\mu\).
- 95 %-ný obojstranný interval spoľahlivosti pre strednú hodnotu \(\mu\) trvania pracovnej operácie,
- 95 %-ný pravostranný interval spoľahlivosti pre strednú hodnotu \(\mu\) trvania pracovnej operácie,
- 95 %-ný ľavostranný interval spoľahlivosti pre strednú hodnotu \(\mu\) trvania pracovnej operácie.
- bodové odhady parametrov \(\mu\) a \(\sigma\),
- 95 %-ný obojstranný interval spoľahlivosti pre strednú hodnotu \(\mu\),
- 95 %-ný obojstranný interval spoľahlivosti pre smerodajnú odchýlku \(\sigma\).
- bodové odhady parametrov \(\mu\) a \(\sigma\),
- 95 %-ný pravostranný interval spoľahlivosti pre strednú hodnotu \(\mu\),
- 95 %-ný ľavostranný interval spoľahlivosti pre rozptyl \(\sigma^2\).
- 95 %-né obojstranné intervaly spoľahlivosti pre rozptyl \(\sigma^2\) a smerodajnú odchýlku \(\sigma\) výkonu sledovaného druhu motora,
- 95 %-né pravostranné intervaly spoľahlivosti pre rozptyl \(\sigma^2\) a smerodajnú odchýlku \(\sigma\) výkonu motora,
- 95 %-né ľavostranné intervaly spoľahlivosti pre rozptyl \(\sigma^2\) a smerodajnú odchýlku \(\sigma\) výkonu motora.
Úloha:
Bol meraný odpor elektrického obvodu [\(\Omega\)] s výsledkami uvedenými v nasledujúcej frekvenčnej tabuľke: \[ \begin{array}{|c|c|c|c|c|c|c|} \hline x_i \a 98 \a 99 \a 100\a 101 \a 102\a 103\\ \hline n_i \a 2 \a 4 \a 6 \a 4 \a 3 \a 1 \\ \hline \end{array} \] Vypočítajte výberové charakteristiky daného výberového súboru.
Bol meraný odpor elektrického obvodu [\(\Omega\)] s výsledkami uvedenými v nasledujúcej frekvenčnej tabuľke: \[ \begin{array}{|c|c|c|c|c|c|c|} \hline x_i \a 98 \a 99 \a 100\a 101 \a 102\a 103\\ \hline n_i \a 2 \a 4 \a 6 \a 4 \a 3 \a 1 \\ \hline \end{array} \] Vypočítajte výberové charakteristiky daného výberového súboru.
Úloha:
Vykonali sme 32 analýz na overenie koncentrácie chemickej látky v roztoku s týmito výsledkami: \[ \begin{array}{|c|c|c|c|c|c|c|c|c|c|c|} \hline x_i \a 9 \a 11 \a 12\a 14 \a 15\a 16 \a 17\a 18\a 20\a 21 \\ \hline n_i \a 1 \a 2 \a 3 \a 4 \a 7 \a 5 \a 4\a 3\a 2 \a 1 \\ \hline \end{array} \] Predpokladáme normálne rozdelenie základného súboru, z ktorého bol realizovaný náhodný výber. Vieme, že rozptyl \(\sigma^2=7{,}4\). Vypočítajte:
Vykonali sme 32 analýz na overenie koncentrácie chemickej látky v roztoku s týmito výsledkami: \[ \begin{array}{|c|c|c|c|c|c|c|c|c|c|c|} \hline x_i \a 9 \a 11 \a 12\a 14 \a 15\a 16 \a 17\a 18\a 20\a 21 \\ \hline n_i \a 1 \a 2 \a 3 \a 4 \a 7 \a 5 \a 4\a 3\a 2 \a 1 \\ \hline \end{array} \] Predpokladáme normálne rozdelenie základného súboru, z ktorého bol realizovaný náhodný výber. Vieme, že rozptyl \(\sigma^2=7{,}4\). Vypočítajte:
Úloha:
Preverovala sa zdatnosť študentov v skoku do výšky. Výsledky dosiahnutej výšky skokov [\(\mathrm{cm}\)] sú zhrnuté v tabuľke: \[ \begin{array}{|c|c|c|c|c|c|c|c|} \hline z_i \a 120 \a 130 \a 140 \a 150 \a 160 \a 170 \a 180 \a 190 \a 200 \a 210 \\ \hline n_i \a 3 \a 5 \a 7 \a 11 \a 12 \a 6 \a 2 \a 2 \a 1 \a 1 \\ \hline \end{array} \] Predpokladáme normálne rozdelenie základného súboru, z ktorého bol realizovaný náhodný výber. Je známa smerodajná odchýlka \(\sigma=20\). Určte:
Preverovala sa zdatnosť študentov v skoku do výšky. Výsledky dosiahnutej výšky skokov [\(\mathrm{cm}\)] sú zhrnuté v tabuľke: \[ \begin{array}{|c|c|c|c|c|c|c|c|} \hline z_i \a 120 \a 130 \a 140 \a 150 \a 160 \a 170 \a 180 \a 190 \a 200 \a 210 \\ \hline n_i \a 3 \a 5 \a 7 \a 11 \a 12 \a 6 \a 2 \a 2 \a 1 \a 1 \\ \hline \end{array} \] Predpokladáme normálne rozdelenie základného súboru, z ktorého bol realizovaný náhodný výber. Je známa smerodajná odchýlka \(\sigma=20\). Určte:
Úloha:
Na obrábacích strojoch sa zisťoval čas v sekundách, ktorý je potrebný na vykonanie pracovnej operácie. Výsledky sú usporiadané v tabuľke intervalového rozdelenia početností: \[ \begin{array}{|c|c|c|c|c|c|c|c|c|c|c|} \hline z_i \a 32 \a 37 \a 42\a 47 \a 52\a 57\a 62\a 67 \\ \hline n_i \a 1 \a 7 \a 33 \a 63 \a 38 \a 5 \a 1\a 2 \\ \hline \end{array} \] Predpokladáme normálne rozdelenie základného súboru, z ktorého bol realizovaný náhodný výber. Vypočítajte:
Na obrábacích strojoch sa zisťoval čas v sekundách, ktorý je potrebný na vykonanie pracovnej operácie. Výsledky sú usporiadané v tabuľke intervalového rozdelenia početností: \[ \begin{array}{|c|c|c|c|c|c|c|c|c|c|c|} \hline z_i \a 32 \a 37 \a 42\a 47 \a 52\a 57\a 62\a 67 \\ \hline n_i \a 1 \a 7 \a 33 \a 63 \a 38 \a 5 \a 1\a 2 \\ \hline \end{array} \] Predpokladáme normálne rozdelenie základného súboru, z ktorého bol realizovaný náhodný výber. Vypočítajte:
Úloha:
Zisťovala sa pevnosť vlákna [\(\mathrm{kg / mm^2}\)]. Merania sa vykonali na desiatich vzorkách s týmito výsledkami: 10,3; 8,8; 9,7; 9,6; 11,2; 10,7; 9,1; 9,5; 10,3; 9,3. Predpokladáme normálne rozdelenie základného súboru, z ktorého bol realizovaný náhodný výber. Určte:
Zisťovala sa pevnosť vlákna [\(\mathrm{kg / mm^2}\)]. Merania sa vykonali na desiatich vzorkách s týmito výsledkami: 10,3; 8,8; 9,7; 9,6; 11,2; 10,7; 9,1; 9,5; 10,3; 9,3. Predpokladáme normálne rozdelenie základného súboru, z ktorého bol realizovaný náhodný výber. Určte:
Úloha:
Merali sme priemer 250 strojových súčiastok. Výsledky merania sú v tabuľke: \[ \begin{array}{|c|c|c|c|c|c|c|c|} \hline z_i \a 963 \a 968 \a 973 \a 978 \a 983 \a 988 \a 993 \a 998 \a 1003 \a 1008 \a 1013 \a 1018 \a 1023 \a 1028 \a 1033 \\ \hline n_i \a 1 \a 5 \a 5 \a 13\a 18 \a 32\a 50 \a 50 \a 37 \a 18\a 8 \a 7 \a 4 \a 1 \a 1 \\ \hline \end{array} \] Predpokladáme normálne rozdelenie základného súboru, z ktorého bol realizovaný náhodný výber. Určte:
Merali sme priemer 250 strojových súčiastok. Výsledky merania sú v tabuľke: \[ \begin{array}{|c|c|c|c|c|c|c|c|} \hline z_i \a 963 \a 968 \a 973 \a 978 \a 983 \a 988 \a 993 \a 998 \a 1003 \a 1008 \a 1013 \a 1018 \a 1023 \a 1028 \a 1033 \\ \hline n_i \a 1 \a 5 \a 5 \a 13\a 18 \a 32\a 50 \a 50 \a 37 \a 18\a 8 \a 7 \a 4 \a 1 \a 1 \\ \hline \end{array} \] Predpokladáme normálne rozdelenie základného súboru, z ktorého bol realizovaný náhodný výber. Určte:
Úloha:
Pri sériových skúškach motorov určitého druhu boli zistené tieto hodnoty výkonu [\(\mathrm{kW}\)]: 159,5; 159,4; 159,6; 159,7; 159,8; 160,1; 160,6; 161,0; 161,5; 161,8; 162,0; 162,5. Predpokladáme normálne rozdelenie základného súboru, z ktorého bol realizovaný náhodný výber. Určte:
Pri sériových skúškach motorov určitého druhu boli zistené tieto hodnoty výkonu [\(\mathrm{kW}\)]: 159,5; 159,4; 159,6; 159,7; 159,8; 160,1; 160,6; 161,0; 161,5; 161,8; 162,0; 162,5. Predpokladáme normálne rozdelenie základného súboru, z ktorého bol realizovaný náhodný výber. Určte:
Doplňujúce zdroje
- Bakytová, H., Ugron, M.: Príklady zo štatistických metód. Alfa, Bratislava, 1972, 289 s.
- Buša, J., Pirč, V., Schrötter, Š.: Numerické metódy, pravdepodobnosť a matematická štatistika. Elfa, Košice, 2006, 166 s., ISBN 80-8073-632-4.
- Daňo, I., Ostertagová, E.: Numerické metódy, pravdepodobnosť a matematická štatistika. Teória, riešené príklady a praktické aplikácie s MATLABom. Equilibria, Košice, 2011, 198 s., ISBN 978-80-89284-74-0.
- Gavalec, M., Kováčová, N., Ostertagová, E., Skřivánek, J: Pravdepodobnosť a matematická štatistika v počítačovom prostredí MATLABu. Elfa, Košice, 2002, 150 s., ISBN 80-89066-05-4.
- Markechová, D., Tirpáková, A., Stehlíková, B.: Základy štatistiky pre pedagógov, UKF v Nitre, 2011,205 s., ISBN 978-80-8094.
- Otipka, P., Šmajstrla, V.: Pravděpodobnost a statistika. TU, Ostrava, 2012, 269 s., ISBN 80-248-1194-4.
V prípade výberového rozptylu sa používajú v odbornej literatúre dve možnosti, a to s \(\frac{1}{n}\) alebo \(\frac{1}{n-1}\). V niektorej literatúre sa výberový rozptyl definuje vzťahom \(S^2=\frac{1}{n}\sum\limits_{i=1}^{n} (x_i-\bar{x})^2\). Tento je však vľavo vychýleným bodovým odhadom rozptylu \(\sigma^2\). Vzťahom \(s^2=\frac{1}{n-1}\sum\limits_{i=1}^{n} (x_i-\bar{x})^2\) definujú tzv. modifikovaný (upravený) výberový rozptyl a označujú ho aj pridaním značky *.