Rozličné témy
reprezentácia času v počítači, pretečenie, enumeračné typy, exit status, štandardné kanály/prúdy
Záznam z prednášky
Reprezentácia dátumu a času
(slide) Vráťme sa teraz k problému, ktorý sme odložili - v štruktúre
struct person, ktorú sme si vytvorili, sme zavrhli možnosť ukladať informáciu o veku osoby vo forme celého čísla typuint. A to hlavne z dôvodu, že samotná aktualizácia veku sa stane problémom - nebudeme vedieť, kedy máme vek u každej jednej osoby aktualizovať a budeme to musieť robiť hromadne pre všetky z nich. Chýbal nám spôsob, akým by sme vedeli reprezentovať dátum narodenia každej osoby.(slide) Dnes sa teda pokúsime odpovedať aj na otázku: Ako je teda reprezentovaný čas v počítači?
Štruktúra pre reprezentáciu dátumu a času
(slide) Čo je vlastne čas a dátum? Len ďalší štruktúrovaný údajový typ. Ak budeme chcieť reprezentovať dátum, jedná sa o štruktúru pozostávajúcu z dňa, mesiaca a roku. Ak zasa čas, bude sa jednať o štruktúru hodiny, minúty, sekundy. Samozrejme môžeme uvažovať aj o milisekundách a mikrosekundách, ale tie nás momentálne nebudú zaujímať.
(slide) Pokúsme sa teda takúto štruktúru, ktorá bude reprezentovať čas aj dátum, vytvoriť sami. V tom najjednoduchšom prevedení môže vyzerať napríklad takto:
struct dt { int sec; int min; int hour; int dom; // day of month int month; int year; int dow; // day of week };Následne ju môžeme inicializovať:
struct dt now = { .sec = 00, .min = 15, .hour = 08, .dom = 13, .mon = 03, // March .year = 2024, .dow = 3 // Wednesday };
Problém “bulharských konštánt”
Ak si všimnete, pre uchovávanie jednotlivých položiek používame údajový typ
int. Ten je samozrejme priveľký, ak chceme uchovávať jednotlivé zložky času. Napríklad pre reprezentáciu hodín potrebujeme len 60 hodnôt, pričom typintje veľký32b. Pre jednoduchosť budeme tento fakt ignorovať.Je tu však položka
.dow, ktorá je zaujímavá v jednej veci. Predstavuje totiž deň v týždni (z ang. day of week), ktorý je reprezentovaný ako číslo. A keďže dní v týždni je 7, aj.dowbude používať 7 hodnôt. Ak však štvrtok má hodnotu3, tak týždeň začína nedeľou s hodnotou0. Ak by som chcel teda overiť, či je dnes piatok, vyzeralo by to takto:if(now.dow == 5){ printf("Uz len dva dni a je tu opat zaciatok " "dalsieho pracovneho tyzdna.\n"); }else{ printf("Este treba pockat.\n"); }Už na predmete Základy algoritmizácie a programovania sme sa snažili o to, aby ste si osvojili si niekoľko dobrých prístupov. Jeden z nich hovorí, že vo svojom kóde by ste nemali používať rozličné “bulharské” konštanty. Ako napr. v našom prípade - čísla, ktoré reprezentujú konkrétne dni. Toto síce ešte nie je ten najhorší prípad, ale pokúsme sa mu predísť. Ako sa teda vyhnúť použitiu konkrétnych nič neznamenajúcich čísel?
Použitie makier
(slide) Jedným z riešení by mohlo byť použitie makier. Vytvorili by sme makro pre každý jeden deň, pričom jeho hodnota by zodpovedala práve danému dňu. Napríklad:
#define SUNDAY 0 #define MONDAY 1 #define TUESDAY 2 #define WEDNESDAY 3 #define THURSDAY 4 #define FRIDAY 5 #define SATURDAY 6Od tohto momentu teda môžeme miesto číselných literálov používať makrá, pretože všade tam, kde bude makro použite, v prvej fáze prekladu ich prekladač všetky zamení za príslušnú hodnotu. Ak by som teda chcel teraz vo svojom programe overiť, či je dnes piatok, tak by to vyzeralo takto:
if(now.dow == FRIDAY){ printf("Uz len dva dni a je tu opat zaciatok " "dalsieho pracovneho tyzdna.\n"); }else{ printf("Este treba pockat.\n"); }
Enumeračný typ
(slide) Jazyk C však používa ešte jeden spôsob, ktorý je známy ako enumeračný typ alebo po slovensky tiež známy pod označením vymenovaný typ. Častokrát sa dá stretnúť aj s označením enumeration alebo enum. Podľa wikipédie je enumeračný typ definovaný ako:
is a data type consisting of a set of named values called elements (or members/enumerals/enumerators) of the type.
Takže ide o údajový typ, pomocou ktorého je možné vytvoriť množinu pomenovaných hodnôt (konštánt) daného typu.
(slide) Najjednoduchšie bude ukázať, ako taký enumeračný údajový typ vyzerá. Vytvoríme teda enumeračný typ, ktorý bude reprezentovať dni v týždni:
enum days { SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY };Ak by som chcel teraz overiť, či je už piatok, predchádzajúci kód zostane nezmenený:
if(now.dow == FRIDAY){ printf("Uz len dva dni a je tu opat zaciatok " "dalsieho pracovneho tyzdna.\n"); }else{ printf("Este treba pockat.\n"); }
Hodnota prvkov enumeračného typu
(slide) Každá položka enumeračného typu je reprezentovaná celým číslom. Môžeme si to jednoducho overiť tým, že si necháme niektorú položku vypísať na obrazovku:
printf("A nedela je: %d\n", SUNDAY);Po preložení a spustení kódu sa nám na obrazovke zobrazí hodnota
0. Takže jednotlivé položky enumeračného typu sú číslované podobne ako sú indexované položky poľa - od0.Enumeračný typ môžeme použiť aj na reprezentáciu mesiacov. Tu akurát nastane problém, že január bude mať hodnotu
0miesto hodnoty1. Tento problém odstránime buď nepoužiteľnou konštantou alebo inicializujeme položky enumeračného typu podobne, ako v prípade inicializácie štruktúry:enum months { JANUARY = 1, FEBRUARY, MARCH, APRIL, MAY, JUNE, JULY, AUGUST, SEPTEMBER, OCTOBER, NOVEMBER, DECEMBER };
Enumeračný typ ako typ premennej
Následne už môžeme rovno aktualizovať štruktúru
struct dto nové typy pre položkymonadow:struct dt { int sec; int min; int hour; int dom; // day of month enum months mon; int year; enum days dow; // day of week };
Príklady použitia enumeračných typov
S enumeračnými typmi sa dá stretnúť na rozličných miestach. Sú fantastickým pomocníkom v rozličných situáciách a ponúkajú jednoduchý spôsob, ako sa zrozumiteľne popasovať s prípadnými “bulharskými” konštantami. Príkladom napr. môžu byť:
(slide) hracie karty, pre ktoré je možné vytvoriť osobitný enumeračný typ ako pre karty, tak aj pre ich hodnoty

(slide) Enumeračný typ pre typ karty môže vyzerať napríklad takto:
enum suit { CLUB, DIAMONDS, HEARTS, SPADES };(slide) údajový typ boolean môžete rovnako zadefinovať pomocou enumeračného typu a nemusíte tak použiť externú knižnicu
stdbool.h:enum boolean { false, true };(slide) úrovne logovacích správ môžu byť rovnako definované pomocou enumeračného typu spolu s hodnotou, ktorá určuje ich váhu:
enum loglevel { DEBUG = 10, INFO = 20, WARNING = 30, ERROR = 40, CRITICAL = 50 };a iné
Unixový čas
Vráťme sa však naspäť k reprezentácii času.
(slide) Interne sa čas zvykne uchovávať vo forme celého čísla, ktoré reprezentuje počet sekúnd od počiatku epochy. Epocha sa začala rátať presne od polnoci (00:00:00) 1. januára 1970. Tento čas je tiež známy pod ďalšími menami, ako Coordinated Universal Time (UTC) alebo POSIX time alebo Epoch time alebo Unixový čas.
Poznámka
Vhodnými ilustráciami pre epochu môže byť napr. pred naším letopočtom / nášho letopočtu alebo pred Kristom a po Kristovi.
(slide) Za ten čas sme mali niekoľko výročí, ako napr.
1000000000alebo1111111111alebo1234567890. Po celom svete sa organizovali rozličné party a oslavy. Proste deti :-D
Zistenie aktuálneho času
(slide) Ak chceme v jazyku C získať hodnotu aktuálneho času, môžeme za tým účelom použiť funkciu
time()z knižnicetime.h. Táto funkcia vracia hodnotu typutime_t. Na prvý pohľad nevieme povedať, čo je to za typ (zrejme je definovaný pomocoutypedef), ale bude to celé číslo, ktoré reprezentuje práve počet sekúnd od počiatku epochy.Príklad použitia si ukážeme na fragmente kódu, ktorý každú sekundu vypíše počet uplynulých sekúnd od počiatku epochy:
#include <stdio.h> #include <time.h> #include <unistd.h> int main(){ while(1){ time_t now = time(NULL); printf("%ld\n", now); sleep(1); } }
Ako je reprezentovaný počet sekúnd v pamäti
Pri tejto príležitosti sa pozrime na jeden skrytý problém, ktorý súvisí s tým, koľko miesta v pamäti zaberá návratová hodnota funkcie
time(). Už vieme, že sa jedná o typtime_t, ktorý sa nachádza v knižnicitime.h(ale tam sa len vkladá z iného hlavičkového súboru…). V skutočnosti je tento typ reprezentovaný typomlong, čo znamená, že v pamäti zaberá8B. To si vieme jednoducho overiť pomocou operátorasizeof():printf("%zu\n", sizeof(time_t));Stále však existujú systémy, ktoré na reprezentáciu používajú štandardný znamienkový integer, čo teda znamená, že v pamäti sa hodnota ukladá na 4B. Aká je teda maximálna hodnota, ktorú je možné takýmto spôsobom zapísať?
Túto hodnotu môžeme jednoducho zistiť vypísaním konštanty
INT_MAX, ktorá udáva maximálnu možnú hodnotu, ktorú je možné zapísať ako celé kladné číslo (signed int). Jej definícia sa nachádza v knižnicilimits.h:#include <stdio.h> #include <limits.h> int main(){ printf("%d\n", INT_MAX); }(slide) Jej hodnota je teda 2147483647, čo je vlastne aj \[\frac{2^{32}}{2} + 1\] Je to teda maximálny počet sekúnd, ktorý je možné reprezentovať pomocou 4B.
Problém roku 2038
(slide) Dátum, na ktorý pripadá tento počet sekúnd, je utorok, 19. januára 2038 o 03:14:07 UTC. Tento problém je tiež známy ako Year 2038 Problem. Otázkou však je, čo príde potom? (slide)
Keďže ale my nie sme novinári z Nových tajmsov, pozrime sa, čo sa udeje na pozadí - spustíme odpočet sami a overíme, či ku dňu zúčtovania naozaj dôjde:
#include <stdio.h> #include <unistd.h> int main(){ int time = 2147483640; while(1){ printf("%d\n", time); sleep(1); time++; } }Aby to bolo zaujímavejšie, použijeme funkciu
strftime(). Táto funkcia dokáže vypísať čas na základe formátovacieho reťazca. Čas je potrebné mať uložený v štruktúrestruct tm. Modifikujeme teda predchádzajúci kód a túto funkciu použijeme:#include <stdio.h> #include <unistd.h> #include <time.h> int main(){ int time = 2147483640; char buffer[200]; while(1){ time_t t = (time_t)time; struct tm *info = localtime(&t); strftime(buffer, sizeof(buffer), "%d.%m.%Y %H:%M:%S", info); printf("%d - %s\n", time, buffer); sleep(1); time++; } }
Pretečenie
Po spustení sa síce žiadny koniec sveta neudial, ale udiala sa iná vec. Ako sa volá?
(slide) Tento problém sa volá pretečenie (z angl. overflow) alebo v tomto prípade môžeme rovno hovoriť o integer overflow.
(slide) Ku pretečeniu dôjde vtedy, keď je
výsledkom aritmetickej operácie číslo, ktoré nie je možné zapísať na uvedený počet bitov (je mimo rozsah).
(slide) Tento problém sa dá jednoducho ilustrovať pomocou tachometra v aute - keď dosiahne max hodnotu 99999, po prejdení ďalšieho kilometra sa vynuluje.
Takže tomuto problému vieme v tomto prípade predísť jednoducho tým, že použijeme vhodne veľký údajový typ. Napríklad
long. Ten nám zabezpečí výrazne viac času, ako typint.V prípade auta by sme potrebovali pridať jedno mechanické koliesko navyše. Tým pádom by sa max. hodnota počítadla najazdených kilometrov zvýšila o celý rád (10x) na 999999.
(slide) Síce sme o tomto probléme povedali všetko, ale ak vás to zaujíma, pozrite si ešte toto krátke video.
Štruktúra v štruktúre
Vráťme sa však opäť k nášmu problému s uchovávaním informácií o osobách. Zadefinovanú štruktúru
struct personvieme teraz rozšíriť o ďalšiu položku, ktorou bude dátum narodenia. Pre našu potrebu jemne zjednodušíme vytvorenú štruktúru a necháme len položky, ktoré definujú dátum. Samotnú štruktúru premenujeme nastruct date:// structure representing date and time struct date { int day; int month; int year; }; // structure representing a person struct person { char name[20]; char surname[30]; char sex; struct date dob; };
Exit Status
(slide) Tentokrát sa vrátime opäť k funkcii
main(). Jej deklarácia vyzerá nasledovne:int main(int argc, char** argv)Pracovať s parametrami príkazového riadku ste sa naučili v rámci predmetu Základy algoritmizácie a programovania v rámci zimného semestra. Spolu sme sa zasa pozreli na význam druhého parametra. Viete však, čo znamená návratová hodnota typu
int? A načo sa používa?(slide) Tejto návratovej hodnote hovoríme exit status. A je to spôsob, akým vieme z našej aplikácie dať vedieť operačnému systému, ako sa naša aplikácia ukončila - či úspešne alebo neúspešne. Ak sa ukončila úspešne, vrátime systému hodnotu
0. Ak sa aplikácia ukončila neúspešne (došlo k zlyhaniu), vrátime hodnotu inú ako je hodnota0. Na základe tejto hodnoty môžeme dokonca identifikovať problém, ku ktorému došlo.Upozornenie
Tu však pozor! Aj napriek tomu, že návratový typ funkcie
main()jeint, jedná sa o 8b hodnotu. To znamená, že hodnoty, ktoré viete z funkciemain()vrátiť, môžu byť len z rozsahu0až255.(slide) V unix-ových systémoch sa viete k hodnote exit status-u dostať pomocou premennej prostredia
$?, ktorá vždy obsahuje exit status posledne ukončeného programu.To si môžeme ukázať na príklade príkazu
ls:Ak vypíšeme obsah existujúceho priečinka, po vypísaní obsahu premennej
$?dostaneme hodnotu0:$ ls $ echo $? 0Ak však necháme vypísať obsah neexistujúceho priečinku alebo priečinku, do ktorého nemáme povolený prístup, dostaneme inú hodnotu:
$ ls neexistujuci.priecinok $ echo $? 2
Toto viete s úspechom využiť vo vlastných skriptoch (ktoré nie sú predmetom záujmu tohto kurzu) a rozlične na vzniknutú situáciu reagovať. Často sa viete stretnúť s tzv. one-linermi v tvare:
ls && echo "success" || echo "failure"Častokrát si však vystačíte len s dvoma hodnotami. Váš program vráti hodnotu
0, keď sa váš program ukončí v poriadku, alebo vráti hodnotu1vtedy, keď sa program skončí s chybou.
(slide) Pre tieto dve hodnoty máme v knižnici
stdlib.hzadefinované dve makrá:EXIT_SUCCESS- Successful termination forexit();evaluates to0.EXIT_FAILURE- Unsuccessful termination forexit();evaluates to a non-zero value.
Štandardné prúdy
(slide) Štandardné prúdy predstavujú základné stavebné bloky pre tvorbu interaktívnych programov v prostredí príkazového riadku.
(slide) Čo to ale je stream? Čo je to prúd? Keď sa pozrieme do prírody napr. na prúd vody, tak vieme, že má dva konce. Na jednom konci prúd začína (pramení) a na druhom konci má výtok. A keď túto ilustráciu prenesieme na rieku, tak po rieke v smere prúdu už naši predkovia napr. splavovali drevo. V našom prípade akurát nebudeme hovoriť o vode, ale o prúde údajov. Prúd je teda niečo, čo dokáže prenášať údaje. V našom prípade sa bude prenášať text.

Čo to ale znamená pre nás? Ak teda hovoríme o tom, že každý prúd má dva konce a štandardné prúdy v Linuxe/Unixe sú základné bloky na tvorbu interaktívnych programov, tak budeme hovoriť o interakcii medzi používateľom a programom. Na jednom konci týchto prúdov bude teda používateľ a na druhom konci bude program. Ako teda teda program komunikuje s používateľom a naopak používateľ s programom?
(slide) Keď sa program spustí, otvoria sa pre neho v unixových systémoch tri štandardné (textové) prúdy alebo tiež nazývané kanály:
stdin- štandardný vstup (z angl. standard input), ktorý slúži pre čítanie vstupu,stdout- štandardný výstup (z angl. standard output), ktorý slúži pre zápis výstupu, astderr- štandardný chybový výstup (z angl. standard error), ktorý slúži pre zápis diagnostického výstupu. Odporúča sa, aby všetky chybové hlášky boli posielané práve do tohto prúdu.
Tieto tri prúdy môžeme vidieť na nasledujúcom obrázku:
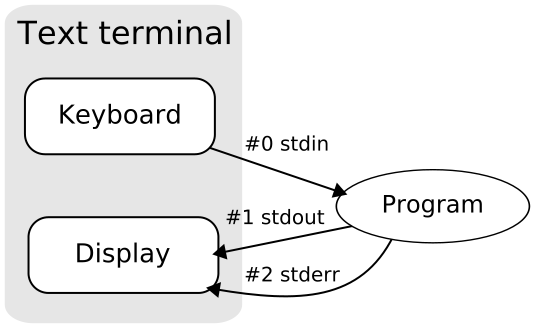
{kind=link}
Príklad
použitia štandardných prúdov s nástrojom figlet
Pozrime sa teraz na to, ako sa s týmito prúdmi pracuje.
(slide) Pre ilustráciu použijem príkaz
figlet, ktorý vytvára veľké znaky pozostávajúce z normálnych znakov. Napríklad:$ figlet "Hello world!" _ _ _ _ _ _ _ | | | | ___| | | ___ __ _____ _ __| | __| | | | |_| |/ _ \ | |/ _ \ \ \ /\ / / _ \| '__| |/ _` | | | _ | __/ | | (_) | \ V V / (_) | | | | (_| |_| |_| |_|\___|_|_|\___/ \_/\_/ \___/|_| |_|\__,_(_)
Štandardný výstup
(stdout)
Začneme tým, čomu chápeme najlepšie - štandardným výstupom. Je to (takmer) čokoľvek, čo program vypíše na obrazovku. Príkladom môže byť už vytvorený
Hello world!:$ figlet "Hello world!" _ _ _ _ _ _ _ | | | | ___| | | ___ __ _____ _ __| | __| | | | |_| |/ _ \ | |/ _ \ \ \ /\ / / _ \| '__| |/ _` | | | _ | __/ | | (_) | \ V V / (_) | | | | (_| |_| |_| |_|\___|_|_|\___/ \_/\_/ \___/|_| |_|\__,_(_)
Štandardný vstup
(stdin)
Štandardný vstup sa v programoch používa na to, ak chceme od používateľa načítať vstup z klávesnice. Napr. sa ho opýtame na meno, ktoré on následne z klávesnice zadá.
Ak nástroj
figletspustíme bez uvedenia textu, ktorý chceme vypísať, otvorí štandardný vstup a každý text, ktorý mu zadáme (stlačíme klávesEnter) okamžite vypíše veľkými písmenami. Štandardný vstup uzavrieme klávesovou skratkouCTRL+D.$ figlet Hello _ _ _ _ | | | | ___| | | ___ | |_| |/ _ \ | |/ _ \ | _ | __/ | | (_) | |_| |_|\___|_|_|\___/ world! _ _ _ __ _____ _ __| | __| | | \ \ /\ / / _ \| '__| |/ _` | | \ V V / (_) | | | | (_| |_| \_/\_/ \___/|_| |_|\__,_(_)
Štandardný chybový výstup
(stderr)
Hovorili sme, že štandardný chybový výstup sa používa na zápis diagnostických správ. To sú napríklad chybové hlášky programu. V nástroji
figlettakúto hlášku môžeme zobraziť napríklad vtedy, ak použijeme neexistujúci prepínač príkazového riadku:$ figlet -h figlet: invalid option -- 'h' Usage: figlet [ -cklnoprstvxDELNRSWX ] [ -d fontdirectory ] [ -f fontfile ] [ -m smushmode ] [ -w outputwidth ] [ -C controlfile ] [ -I infocode ] [ message ]
Presmerovanie výstupu
Lenže - v čom sa líši štandardný výstup od štandardného chybového výstupu? Obe hlášky sa zobrazia na monitore a na pohľad medzi nimi nie je žiaden rozdiel.
Rozdiel je totiž práve v tom, ktorým kanálom sa na ten výstup dostali. A to, že tá cesta bola rozličná si ukážeme pomocou tzv. presmerovania.
Presmerovanie funguje podobne ako v reálnom živote. Ak sme si ako ilustráciu zvolili rieku, tak vieme, že keď si dáme záležať, vieme ju odraziť tak, že prestane tiecť pôvodným korytom. Proste presmerujeme jej tok.
Podobne vieme presmerovať ako výstup, tak aj vstup programu, napr. do/zo súboru.
(slide) Na presmerovanie výstupu používame operátor
>a na presmerovanie vstupu operátor<. Použitie si ukážme postupne na príklade.Začnem tým, čo už vieme - vygenerujem cez
figlettextHello world!:$ figlet "Hello world!" _ _ _ _ _ _ _ | | | | ___| | | ___ __ _____ _ __| | __| | | | |_| |/ _ \ | |/ _ \ \ \ /\ / / _ \| '__| |/ _` | | | _ | __/ | | (_) | \ V V / (_) | | | | (_| |_| |_| |_|\___|_|_|\___/ \_/\_/ \___/|_| |_|\__,_(_)Ak nechcem výsledok fotiť a orezávať ako obrázok, ale chcem ho napríklad použiť vo svojom programe, tak ho uložím do súboru tak, že presmerujem štandardný výstup z programu
figletdo súboruoutput:$ figlet "Hello world!" > output $ cat output _ _ _ _ _ _ _ | | | | ___| | | ___ __ _____ _ __| | __| | | | |_| |/ _ \ | |/ _ \ \ \ /\ / / _ \| '__| |/ _` | | | _ | __/ | | (_) | \ V V / (_) | | | | (_| |_| |_| |_|\___|_|_|\___/ \_/\_/ \___/|_| |_|\__,_(_)Vstup pre
figletmôžem mať uložený v osobitnom súbore, napríkladinput. Ak chcem použiť obsah tohto súboru ako vstup, tak presmerujem štandardný vstup do programufigletzo súboruintput:$ figlet < input _ _ _ _ _ _____ _ | | | | || | ___| | _|___ / _ __| | | |_| | || |_ / __| |/ / |_ \| '__| | | _ |__ _| (__| < ___) | | |_| |_| |_| |_| \___|_|\_\____/|_| (_)Ak dôjde ku chybe, bude vypísaná na obrazovku. Ak však chceme chybové hlášky filtrovať a odlíšiť ich tak od štandardného výstupu, tak presmerujeme štandardný chybový výstup z programu
figletdo súboruerror. Použijeme na to rovnaký operátor ako v prípade presmerovania štandardného výstupu, akurát pred neho napíšeme číslo kanála. Tým odlíšime štandardný výstup od štandardného chybového výstupu. Takže ak použijeme neexistujúci prepínač pre nástrojfiglet, chybová hláška bude presmerovaná:$ figlet -h 2> error $ cat error figlet: invalid option -- 'h' Usage: figlet [ -cklnoprstvxDELNRSWX ] [ -d fontdirectory ] [ -f fontfile ] [ -m smushmode ] [ -w outputwidth ] [ -C controlfile ] [ -I infocode ] [ message ]Samozrejme presmerovať môžeme naraz všetky štandardné prúdy:
figlet < input > output 2> error
Práca so štandardnými prúdmi v jazyku C
(slide) Teraz sa však pozrime na to, ako sa so štandardnými prúdmi pracuje v jazyku C. V rámci ilustrácie vytvoríme jednoduchú implementáciu nástroja
rev, ktorý vypíše obsah súboru na obrazovku odzadu. Ak súbor neuvedieme, bude pracovať so štandardným vstupom.Začneme s tým, že overíme počet argumentov príkazového riadku, ktorý musí byť max. 2:
- názov spúšťaného programu, a
- názov súboru, ktorý chceme vypísať odzadu
Ak bude počet argumentov vyšší, vypíšeme chybu.
Počiatočná implementácia v súbore
rev.cbude vyzerať nasledovne:#include <stdio.h> #include <stdlib.h> int main(int argc, char* argv[]){ if(argc > 2){ printf("Error: too many parameters.\n"); exit(EXIT_FAILURE); } }Lenže keď program otestujeme, výpis bude realizovaný do štandardného výstupu. To vieme otestovať jednoducho presmerovaním štandardného výstupu do súboru. Ten však po spustení zostane prázdny a chybová hláška bude na obrazovke:
$ ./rev jano fero jozo 2> error Error: too many parameters.(slide) V linuxových systémoch sú aj štandardné prúdy reprezentované ako súbory. To so sebou nesie obrovské výhody, pretože s nimi môžeme pracovať ako s ktorýmkoľvek iným súborom - vieme do nich zapisovať a vieme z nich čítať.
Súbory, ktoré reprezentujú jednotlivé prúdy, sú definované v štandardnej knižnici
stdio.h. Jedná sa o premenné:FILE* stdin;- súbor reprezentuje štandardný vstupFILE* stdout;- súbor reprezentuje štandardný výstupFILE* stderr;- súbor reprezentuje štandardný chybový výstup
(slide) Ak teda chceme vypísať chybovú hlášku do štandardného chybového výstupu, urobíme to pomocou funkcie
fprintf(), kde súbor, do ktorého budeme chybovú hlášku vypisovať, budestderr:fprintf( stderr, "Error: too many parameters.\n" );Ak teraz program otestujeme, bude už pracovať ako má:
$ ./rev jano fero jozo 2> error $ cat error Error: too many parameters.Ak používateľ zadá názov súboru, pokúsime sa ho otvoriť. Ak súbor neexistuje, ukončíme program so správou v štandardnom chybovom prúde:
FILE* fp; if(argc == 2){ fp = fopen(argv[1], "r"); // if file can't be opened, then error if(fp == NULL){ fprintf(stderr, "Error: file %s can't be opened.\n", argv[1]); exit(EXIT_FAILURE); } }Ak však používateľ súbor nezadá, použijeme rovno štandardný vstup:
FILE* fp = stdin;Následne vytvoríme jednoduchú rekurzívnu funkciu, ktorá
- načíta znak
- pokiaľ po načítaní znaku nie je koniec súboru, tak
- zavolá samu seba
- vypíše už načítaný znak do štandardného výstupu
void read_char(FILE* fp){ char ch = fgetc(fp); if(!feof(fp)){ read_char(fp); fprintf(stdout, "%c", ch); } }Následne funkciu zavoláme a po skončení uzavrieme otvorený súbor. Riešenie úlohy môže vyzerať napr. takto:
#include <stdio.h> #include <stdlib.h> void read_char(FILE* fp){ char ch = fgetc(fp); if(!feof(fp)){ read_char(fp); fprintf(stdout, "%c", ch); } } int main(int argc, char* argv[]){ FILE* fp = stdin; // read name of file to open // if too much params, then error if(argc > 2){ fprintf(stderr, "Error: too many parameters.\n"); exit(EXIT_FAILURE); } if(argc == 2){ fp = fopen(argv[1], "r"); // if file can't be opened, then error if(fp == NULL){ fprintf(stderr, "Error: file %s can't be opened.\n", argv[1]); exit(EXIT_FAILURE); } } read_char(fp); // close file fclose(fp); }Ak teraz program spustíme bez názvu súboru, otvorí sa vstup zo štandardného vstupu, kde môžeme napísať text, ktorý chceme obrátiť. Zadávanie vstupu ukončíme stlačením klávesovej skratky
CTRL+D:$ ./rev hello world this is test tset si siht dlrow olleh $To, že vieme pracovať aj so štandardným vstupom, so sebou nesie množstvo výhod. Napr. môžeme zreťaziť výstup jedného programu so vstupom druhého tým, že medzi nimi vytvoríme rúru (z angl. pipe).
$ echo "Hello world!" | ./rev !dlrow olleHAk reverzneme výstup ešte raz, tak dostaneme pôvodnú správu:
$ echo "Hello world!" | ./rev | ./rev Hello world!