Vyhľadávanie a triedenie
vyhľadávanie a triedenie zoznamov, knižnica stdlib.h,
funkcie qsort(), bsearch()
Záznam z prednášky
Úvod
(slide) Naposledy sme si ukázali, ako vytvoriť štruktúrovaný údajový typ, pomocou ktorého vieme udržiavať informácie o osobách. Vieme ho načítať zo súboru (a do súboru aj uložiť) a celý vypísať na obrazovku.
Pri práci s poliami nás však budú zaujímať dve základné operácie, ktoré vieme vykonávať:
- Vyhľadávanie, a
- triedenie.
O týchto operáciách ste hovorili už na predmete Základy algoritmizácie a programovania, kedy ste do polí ukladali základné údajové typy. Dnes sa pozrieme na to, ako zabezpečiť tieto operácie v prípade polí so štruktúrovanými údajovými typmi.
Lineárne vyhľadávanie
Lineárne vyhľadávanie už poznáme - doteraz sme však hľadali len v poliach jednoduchých údajových typov. Ako bude vyzerať táto operácia nad zoznamom objektov typu štruktúra?
(slide) Jednoduchú reprezentáciu lineárneho vyhľadávania ste si vytvorili už v predmete Základy algoritmizácie a programovania. Vyzerala takto:
int search(int data[], size_t size, int needle){ for(size_t idx=0; idx < size; idx++){ if(data[idx] == needle){ return idx; } } return -1; }Čo všetko budeme potrebovať upraviť pre použitie vyhľadávania nad poľom štruktúr?
Vyhľadanie osoby podľa priezviska
Vytvoríme funkciu, pomocou ktorej budeme vedieť v danom poli vyhľadať konkrétnu osobu na základe jej priezviska:
int search_by_surname(const struct person data[], const size_t size, const char surname[]){ for(size_t idx=0; idx < size; idx++){ if(strcmp(data[idx].surname, surname) == 0){ return idx; } } return -1; }
Vyhľadanie osoby podľa mena priezviska
Rovnako tak môžeme vytvoriť funkciu, pomocou ktorej budeme vedieť v danom poli vyhľadať konkrétnu osobu na základe mena a priezviska:
int search_by_surname_and_age(const struct person data[], const size_t size, const char surname[], const char name[]){ for(size_t idx=0; idx < size; idx++){ if(strcmp(data[idx].surname, surname) == 0 && strcmp(data[idx].name, name) == 0){ return idx; } } return -1; }Celý kód bude teda vyzerať nasledovne:
#include <stdio.h> #include <string.h> // structure representing a person struct person { char name[20]; char surname[30]; char sex; // M, F size_t age; }; // Search person by surname in the list of data of given size int search_by_surname(const struct person data[], const size_t size, const char surname[]){ for(size_t idx=0; idx < size; idx++){ if(strcmp(data[idx].surname, surname) == 0){ return idx; } } return -1; } // Search person by name and surname in the list of data // of given size int search_by_surname_and_age(const struct person data[], const size_t size, const char surname[], const char name[]){ for(size_t idx=0; idx < size; idx++){ if(strcmp(data[idx].surname, surname) == 0 && strcmp(data[idx].name, name) == 0){ return idx; } } return -1; } // Print person object on screen void print_person(struct person person){ printf("%s %s is %c.\n", person.name, person.surname, person.sex ); } int main(){ // open file for reading FILE* fp = fopen("persons.bin", "rb"); // read size first size_t size; fread(&size, sizeof size, 1, fp); // declare list of persons struct person list[size]; // populate list for(size_t i = 0; i < size; i++){ fread(&list[i], sizeof list[i], 1, fp); } fclose(fp); // traverse the list for(size_t i = 0; i < size; i++){ printf("%zu: ", i); print_person(list[i]); } // search char *f_surname = "Plum"; int f_idx = search_by_surname(list, size, f_surname); printf("Position of %s is %d\n", f_surname, f_idx); }
Štandardná knižnica
(slide) V praxi však budete málokedy písať vlastné funkcie pre vyhľadávanie prvkov alebo pre zotriedenie zoznamu prvkov. Proste využijete funkcie, ktoré sú už pre tento účel pripravené.
V tomto prípade môžeme napríklad využiť funkciu
bsearch()z knižnicestdlib.h, ktorá implementuje tzv. binárne vyhľadávanie. A už z predmetu Základy algoritmizácie a programovania viete, že v porovnaní s lineárnym vyhľadávaním, má binárne vyhľadávanie lepšiu zložitosť.
Lineárne vs Binárne vyhľadávanie
(slide) Pokúsme sa porovnať vlastnosti oboch algoritmov na vyhľadávanie:
Lineárne vyhľadávanie Binárne vyhľadávanie zložitosť \[\mathcal{O}(n)\] \[\mathcal{O}(\log_2{}(n))\] najlepší prípad \[\mathcal{O}(1)\] \[\mathcal{O}(1)\] najhorší prípad \[\mathcal{O}(n)\] \[\mathcal{O}(\log_{2}(n))\] prerekvizity žiadne zotriedený zoznam prístup iteratívny rozdeľ a panuj (slide) Pozrime sa teraz na porovnanie cez čísla. V nasledujúcej tabuľke je vidieť porovnanie oboch algoritmov. Tu je vidieť, aký je najhorší prípad pri hľadaní prvku pri použití oboch algoritmov vzhľadom na množstvo prvkov v zozname/poli. Jasne vidieť, že binárnym vyhľadávaním sme schopní hľadaný prvok nájsť za výrazne menší počet krokov ako v prípade lineárneho vyhľadávania.
\[n\] 10 100 1 000 10 000 100 000 \[\mathcal{O}(n)\] 10 100 1 000 10 000 100 000 \[\mathcal{O}(\log_2{}(n))\] 3.3 6.6 10 13.3 16.6 (slide) Porovnať môžeme obe zložitosti aj graficky. Na x-ovej osi sa nachádza počet prvkov a na y-ovej osi sa nachádza počet krokov/prístupov, ktoré potrebujeme vykonať na nájdenie hľadaného prvku. Ako je vidieť, zložitosť lineárneho vyhľadávania má lineárny priebeh, zatiaľ čo zložitosť binárneho vyhľadávania má logaritmický priebeh.
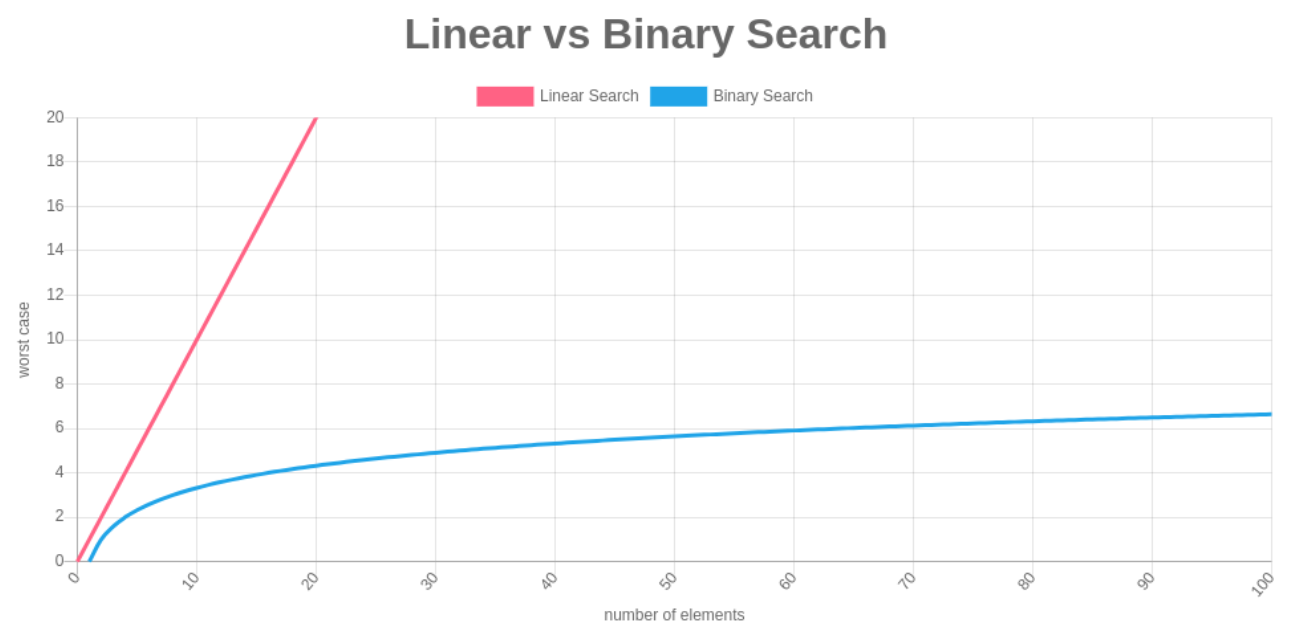
Triedenie zoznamov
pomocou funkcie qsort()
Ak však chceme implementovať binárne vyhľadávanie pomocou funkcie
bsearch(), prvky už musia byť zotriedené. V opačnom prípade fungovať nebude. V štandardnej knižnici sa nachádza implementácia algoritmu triedenia quick sort, ktorú môžeme využiť zavolaním funkcieqsort().(slide) Deklarácia funkcie
qsort()vyzerá nasledovne:void qsort(void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *));Význam jednotlivých parametrov je nasledovný:
base- začiatok zoznamu/poľanmemb- počet prvkov zoznamu/poľasize- veľkosť v pamäti, ktorú zaberá jeden prvok zoznamu/poľacompar- adresa na funkciu, ktorá porovná dva prvky zoznamu navzájom
Vytvorenie porovnávacej funkcie
(slide) Začneme teda tým, že vytvoríme funkciu
cmp_by_surname(), ktorá umožní porovnať dve premenné typustruct personna základe ich priezviska. Funkcia vráti hodnotu:- menšiu ako 0, ak ľavé priezvisko (prvý parameter funkcie) je v poradí pred pravým priezviskom (druhým parametrom funkcie)
- väčšiu ako 0, ak sú priezviská v opačnom poradí
- rovnú 0, ak budú priezviská rovnaké
Výsledná podoba funkcie
cmp_by_surname()bude vyzerať nasledovne:int cmp_by_surname(const void* p1, const void* p2){ struct person* person1 = (struct person*)p1; struct person* person2 = (struct person*)p2; int result = strcmp(person1->surname, person2->surname); // printf("comparing %s vs %s = %d\n", // person1->surname, person2->surname, result); return result; }Následne už len aktualizujeme výsledný kód z minulého týždňa tak, že necháme výsledný zoznam usporiadať pomocou funkcie
qsort()a takto ho usporiadaný vypíšeme na obrazovku:#include <stdio.h> #include <stdlib.h> #include <string.h> // structure representing a person struct person { char name[20]; char surname[30]; char sex; size_t age; }; // Search person by surname in the list // of data of given size int search_by_surname(const struct person data[], const size_t size, const char surname[]){ for(size_t idx=0; idx < size; idx++){ if(strcmp(data[idx].surname, surname) == 0){ return idx; } } return -1; } // Print person object on screen void print_person(const struct person person){ printf("%s %s is %c.\n", person.name, person.surname, person.sex ); } int cmp_by_surname(const void* p1, const void* p2){ struct person* person1 = (struct person*)p1; struct person* person2 = (struct person*)p2; return strcmp(person1->surname, person2->surname); } int main(){ // read the nr of persons printf("Enter the number of persons: "); int size; scanf("%d", &size); // declare list of persons struct person list[size]; // populate list for(size_t i = 0; i < size; i++){ printf("Enter %zu person: ", i); scanf("%s %s %c", list[i].name, list[i].surname, &list[i].sex); } printf("\n"); // traverse the list for(size_t i = 0; i < size; i++){ printf("%zu: ", i); print_person(list[i]); } // sort qsort(list, size, sizeof(struct person), cmp_by_surname); // traverse the list for(size_t i = 0; i < size; i++){ printf("%zu: ", i); print_person(list[i]); } }
Vyhľadávanie pomocou
funkcie bsearch()
(slide) Deklarácia funkcie
bsearch(), ktorá implementuje binárne vyhľadávanie nad zoznamom/poľom, vyzerá nasledovne:void *bsearch(const void *key, const void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *));Význam jednotlivých parametrov je nasledovný:
key- adresa prvku, ktorý má nastavené príslušné položky, na základe ktorých chceme vyhľadávaťbase- začiatok zoznamu/poľanmemb- počet prvkov zoznamu/poľasize- veľkosť v pamäti, ktorú zaberá jeden prvok zoznamu/poľacompar- adresa na funkciu, ktorá porovná dva prvky zoznamu navzájom
Ako funkciu pre porovnanie dvoch prvkov môžeme použiť rovnakú funkciu ako pre zotriedenie zoznamu. Takže už len rozšírime predchádzajúcu verziu kódu o nasledujúci fragment:
// search struct person key = { .surname = "Gray" }; struct person* result = bsearch(&key, list, size, sizeof(struct person), cmp_by_surname); if(result != NULL){ printf("found %s %s, who is %c\n", result->name, result->surname, result->sex); }else{ printf("entry not found\n"); }
Záver
Na tejto a minulej prednáške si predstavili štruktúry, štruktúrované údajové typy a prácu s nimi. Ukázali sme si, ako je možné takto reprezentované údaje ukladať do súboru (serializovať) a zo súboru ich načítavať (deserializovať). Dnes sme si ukázali, ako je možné v zoznamoch obsahujúcich štruktúrované údaje vyhľadávať a ako je možné ich triediť.
Aj napriek tomu, že organizácia údajov do štruktúr prináša výhody, vytváranie zoznamov spôsobom, ktorý sme si ukázali, nie je vždy úplne praktický. Stále je tu jedno obrovské obmedzenie - musíme poznať počet prvkov zoznamu pred jeho vytvorením a počas jeho existencie ho nesmieme meniť (minimálne zväčšovať).
To, ako sa popasovať s týmto problémom si ukážeme na niektorej z ďalších prednášok.